Custom Policies
Policy Creation
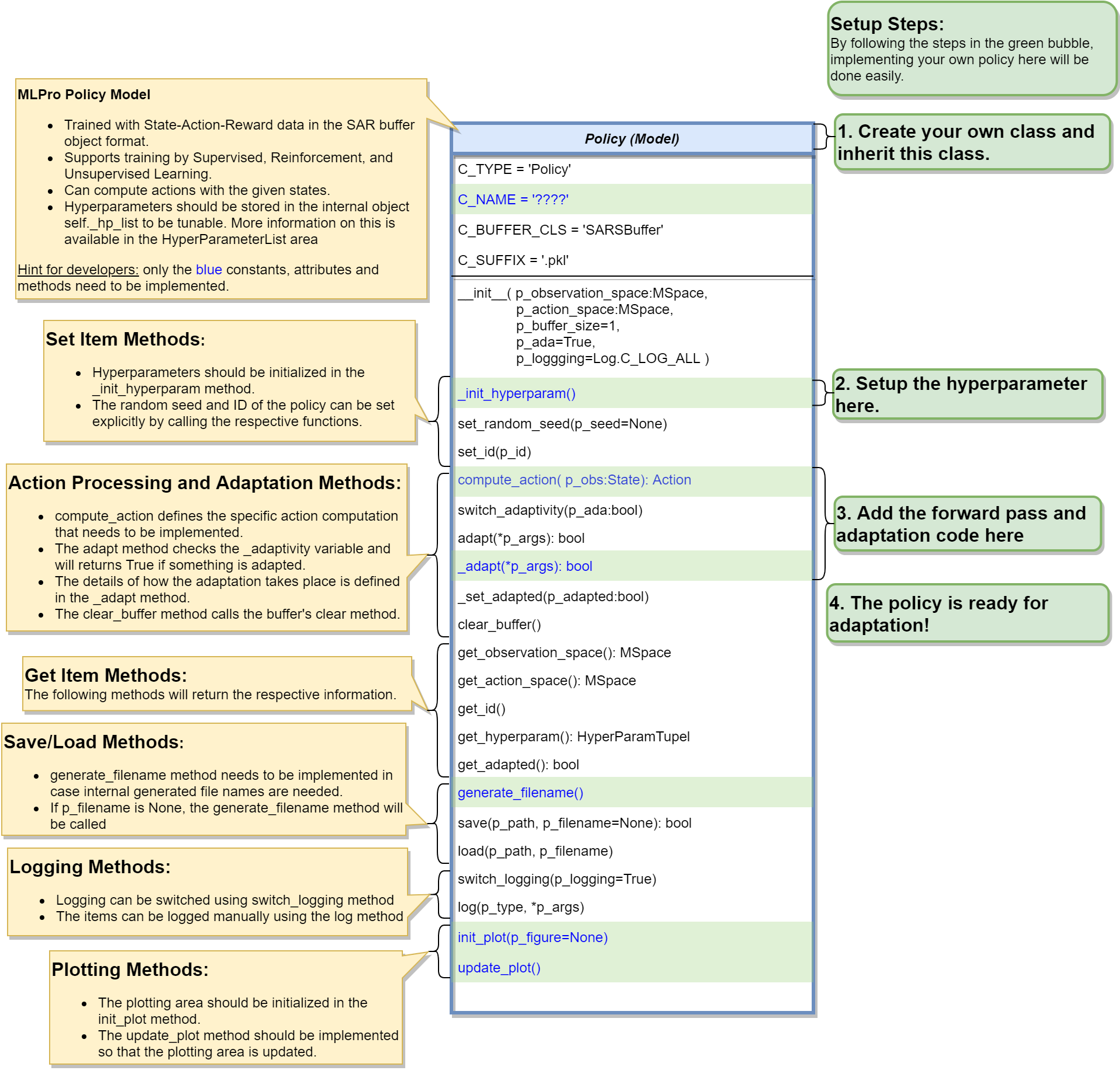
To create a RL policy that satisfies MLPro interface is pretty direct. You just require to assure that the RL policy consists at least these following 3 main functions:
from mlpro.rl.models import * class MyPolicy(Policy): """ Creates a policy that satisfies mlpro interface. """ C_NAME = 'MyPolicy' def __init__(self, p_state_space:MSpace, p_action_space:MSpace, p_ada=True, p_logging=True): """ Parameters: p_state_space State space object p_action_space Action space object p_ada Boolean switch for adaptivity p_logging Boolean switch for logging functionality """ super().__init__(p_ada=p_ada, p_logging=p_logging) self._state_space = p_state_space self._action_space = p_action_space self.set_id(0) def adapt(self, *p_args) -> bool: """ Adapts the policy based on State-Action-Reward (SAR) data that will be expected as a SAR buffer object. Please call super-method at the beginning of your own implementation and adapt only if it returns True. Parameters: p_arg[0] SAR Buffer object """ if not super().adapt(*p_args): return False .... return True def clear_buffer(self): """ Intended to clear internal temporary attributes, buffers, ... Can be used while training to prepare the next episode. """ .... def compute_action(self, p_state:State) -> Action: """ Specific action computation method to be redefined. Parameters: p_state State of environment Returns: Action object """ ....
This class represents the policy of a single-agent. It is adaptive and can be trained with State-Action-Reward (SAR) data that will be expected as a SAR buffer object.
The three main learning paradigms of machine learning to train a policy are supported:
Training by Supervised Learning: The entire SAR data set inside the SAR buffer shall be adapted.
Training by Reinforcement Learning: The latest SAR data record inside the SAR buffer shall be adapted.
Training by Unsupervised Learning: All state data inside the SAR buffer shall be adapted.
Furthermore a policy class can compute actions from states.
Hyperparameters of the policy should be stored in the internal object self._hp_list, so that they can be tuned from outside. Optionally a policy-specific callback method can be called on changes. For more information see class HyperParameterList.
To set up a hyperparameter space, please refer to our how to File 04 or here.
Policy from Third Party Packages
In addition, we are planning to reuse Ray RLlib in the near future. For more updates, please click here.
Algorithm Checker
A test script using unittest to check the develop policies will be available soon!