Howto RL-ATT-002: Train and Reload Single Agent using Stagnation Detection Cartpole Discrete (MuJoCo)
Prerequisites
- Please install the following packages to run this examples properly:
Executable code
## -------------------------------------------------------------------------------------------------
## -- Project : MLPro - A Synoptic Framework for Standardized Machine Learning Tasks
## -- Package : mlpro.rl.examples
## -- Module : howto_rl_att_002_train_and_reload_single_agent_mujoco_sd_cartpole_discrete.py
## -------------------------------------------------------------------------------------------------
## -- History :
## -- yyyy-mm-dd Ver. Auth. Description
## -- 2023-03-04 1.0.0 DA Creation as derivate of howto_rl_agent_021
## -- 2023-03-07 1.0.1 MRD Renamed
## -- 2023-03-27 1.0.2 DA Refactoring
## -------------------------------------------------------------------------------------------------
"""
Ver. 1.0.2 (2023-03-27)
As in Howto RL AGENT 021, this module shows how to train a single agent with SB3 Policy on Discrete
Cartpole MuJoCo Environment. In opposite to howto 021, stagnation detection is used to automatically
end the training if no further progress can be made.
You will learn:
1. How to use MLPro's RLScenario class.
2. How to create sb3 policy object.
3. How to create SB3 policy in MLPro.
4. How to setup and run RLTraining in MLPro.
"""
from stable_baselines3 import PPO
from mlpro.rl import *
from mlpro.wrappers.sb3 import WrPolicySB32MLPro
from mlpro.rl.pool.envs.cartpole import CartpoleMujocoDiscrete
from pathlib import Path
class MyScenario(RLScenario):
C_NAME = "Matrix"
def _setup(self, p_mode, p_ada: bool, p_visualize: bool, p_logging) -> Model:
# 1.1 Setup environment
self._env = CartpoleMujocoDiscrete(p_logging=logging, p_visualize=visualize)
# 1.2 Setup Policy From SB3
policy_sb3 = PPO(policy="MlpPolicy", n_steps=10, env=None, _init_setup_model=False, device="cpu", seed=1)
# 1.3 Wrap the policy
policy_wrapped = WrPolicySB32MLPro(
p_sb3_policy=policy_sb3,
p_cycle_limit=self._cycle_limit,
p_observation_space=self._env.get_state_space(),
p_action_space=self._env.get_action_space(),
p_ada=p_ada,
p_visualize=p_visualize,
p_logging=p_logging,
)
# 1.4 Setup standard single-agent with own policy
return Agent(
p_policy=policy_wrapped, p_envmodel=None, p_name="Smith", p_ada=p_ada, p_visualize=p_visualize, p_logging=p_logging
)
# 3 Create scenario and run some cycles
if __name__ == "__main__":
# Parameters for demo mode
cycle_limit = 20000
adaptation_limit = 0
stagnation_limit = 5
eval_frequency = 10
eval_grp_size = 5
logging = Log.C_LOG_WE
visualize = True
path = str(Path.home())
else:
# Parameters for internal unit test
cycle_limit = 50
adaptation_limit = 5
stagnation_limit = 5
eval_frequency = 2
eval_grp_size = 1
logging = Log.C_LOG_NOTHING
visualize = False
path = str(Path.home())
# 2 Create scenario and start training
training = RLTraining(
p_scenario_cls=MyScenario,
p_cycle_limit=cycle_limit,
p_adaptation_limit=adaptation_limit,
p_stagnation_limit=stagnation_limit,
p_eval_frequency=eval_frequency,
p_eval_grp_size=eval_grp_size,
p_path=path,
p_visualize=visualize,
p_logging=logging,
)
# 3 Training
training.run()
filename_scenario = training.get_scenario().get_filename()
# 4 Reload the scenario
if __name__ == '__main__':
input( '\nTraining finished. Press ENTER to reload and run the scenario...\n')
scenario = MyScenario.load( p_path = training.get_training_path() + os.sep + 'scenario',
p_filename = filename_scenario )
# 5 Reset Scenario
scenario.reset()
# 6 Run Scenario
scenario.run()
if __name__ != '__main__':
from shutil import rmtree
rmtree(training.get_training_path())
else:
input( '\nPress ENTER to finish...')
Results
The MuJoCo Cartpole environment window appears during training and shows an improved control behavior after a while. After the training, the related scenario is reloaded and run for a further episode to demonstrate the final control behavior.
The training itself is terminated due to automatic stagnation detection. The chart below shows the training progress and the ending at the point of maximum possible reward:
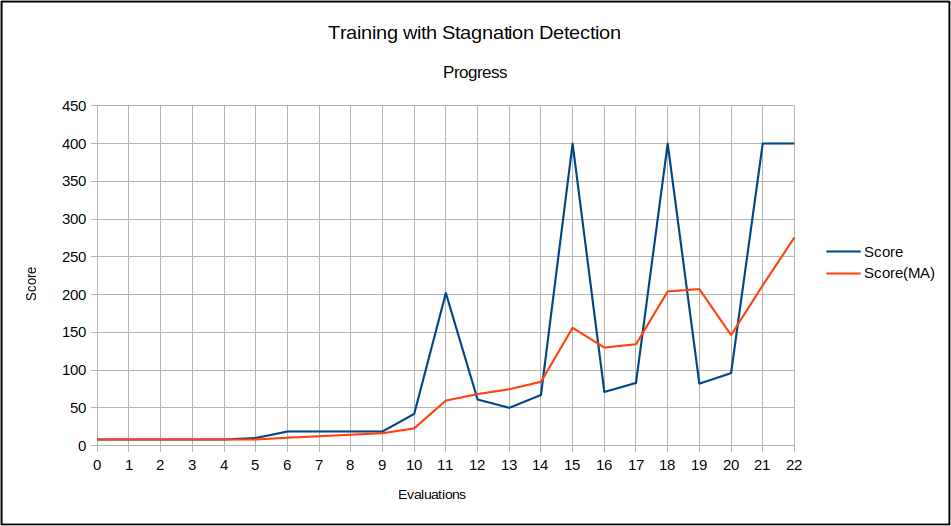
- After termination the local result folder contains the training result files:
agent_actions.csv
env_rewards.csv
env_states.csv
evaluation.csv
summary.csv
scenario
Cross Reference