Howto RL-ENV-005: Run Agent with random policy on double pendulum mujoco environment
Prerequisites
Please install the following packages to run this examples properly:
Executable code
## -------------------------------------------------------------------------------------------------
## -- Project : MLPro - A Synoptic Framework for Standardized Machine Learning Tasks
## -- Package : mlpro.rl.examples
## -- Module : howto_rl_env_005_run_agent_with_random_policy_on_double_pendulum_mujoco_environment.py
## -------------------------------------------------------------------------------------------------
## -- History :
## -- yyyy-mm-dd Ver. Auth. Description
## -- 2022-09-17 0.0.0 MRD Creation
## -- 2022-12-11 0.0.1 MRD Refactor due to new bf.Systems
## -- 2022-12-11 1.0.0 MRD First Release
## -- 2023-01-07 1.0.1 MRD Add State Mapping between MuJoCo model and Environment State Space
## -- 2023-01-27 1.1.0 MRD Implement Pendulum Environment, refactor due to different MuJoCo
## -- mechanism
## -- 2023-02-13 1.1.1 MRD Refactor
## -- 2023-02-23 1.2.0 DA Renamed
## -------------------------------------------------------------------------------------------------
"""
Ver. 1.2.0 (2023-02-23)
This module shows how to run a random policy on Double Pendulum with MuJoCo Simulation.
You will learn:
1) How to set up an own agent using MLPro's builtin random actions policy
2) How to set up an own RL scenario including your agent and MLPro's double pendulum environment
3) How to integrate MuJoCo as the Simulation
4) How to reset and run your own scenario
"""
import random
import numpy as np
import os
import mlpro
from mlpro.bf.ml import Model
from mlpro.bf.ops import Mode
from mlpro.bf.various import Log
from mlpro.rl.models_agents import Policy, Agent
from mlpro.rl.models_train import RLScenario
from mlpro.bf.systems import State, Action
from mlpro.rl.models_env_ada import SARSElement
from mlpro.rl.models_env import Environment
from mlpro.rl.models_agents import Reward
from mlpro.bf.systems import *
# 1 Implement the Environment
class PendulumEnvironment (Environment):
C_NAME = 'PendulumEnvironment'
C_REWARD_TYPE = Reward.C_TYPE_OVERALL
def __init__(self,
p_mode=Mode.C_MODE_SIM,
p_mujoco_file=None,
p_frame_skip: int = 1,
p_state_mapping=None,
p_action_mapping=None,
p_camera_conf: tuple = (None, None, None),
p_visualize: bool = False,
p_logging=Log.C_LOG_ALL):
super().__init__(p_mode=p_mode,
p_mujoco_file=p_mujoco_file,
p_frame_skip=p_frame_skip,
p_state_mapping=p_state_mapping,
p_action_mapping=p_action_mapping,
p_camera_conf=p_camera_conf,
p_visualize=p_visualize,
p_logging=p_logging)
self._state = State(self._state_space)
self.reset()
def _compute_reward(self, p_state_old: State = None, p_state_new: State = None) -> Reward:
reward = Reward(self.C_REWARD_TYPE)
reward.set_overall_reward(1)
return reward
def _reset(self, p_seed=None) -> None:
pass
# 1 Implement your own agent policy
class MyPolicy (Policy):
C_NAME = 'MyPolicy'
def set_random_seed(self, p_seed=None):
random.seed(p_seed)
def compute_action(self, p_state: State) -> Action:
# 1.1 Create a numpy array for your action values
my_action_values = np.zeros(self._action_space.get_num_dim())
# 1.2 Computing action values is up to you...
for d in range(self._action_space.get_num_dim()):
my_action_values[d] = np.random.uniform(-50, 50)
# 1.3 Return an action object with your values
return Action(self._id, self._action_space, my_action_values)
def _adapt(self, p_sars_elem: SARSElement) -> bool:
# 1.4 Adapting the internal policy is up to you...
self.log(self.C_LOG_TYPE_W, 'Sorry, I am a stupid agent...')
# 1.5 Only return True if something has been adapted...
return False
# 2 Implement your own RL scenario
class MyScenario (RLScenario):
C_NAME = 'Matrix'
def _setup(self, p_mode, p_ada: bool, p_visualize:bool, p_logging) -> Model:
# 2.1 Setup environment
model_file = os.path.join(os.path.dirname(mlpro.__file__), "bf/systems/pool/mujoco", "doublependulum.xml")
self._env = PendulumEnvironment(p_logging=logging, p_mujoco_file=model_file, p_visualize=visualize)
# 2.2 Setup standard single-agent with own policy
return Agent( p_policy=MyPolicy( p_observation_space=self._env.get_state_space(),
p_action_space=self._env.get_action_space(),
p_buffer_size=1,
p_ada=p_ada,
p_visualize=p_visualize,
p_logging=p_logging),
p_envmodel=None,
p_name='Smith',
p_ada=p_ada,
p_visualize=p_visualize,
p_logging=p_logging)
# 3 Create scenario and run some cycles
if __name__ == "__main__":
# 3.1 Parameters for demo mode
cycle_limit = 2000
logging = Log.C_LOG_ALL
visualize = True
else:
# 3.2 Parameters for internal unit test
cycle_limit = 10
logging = Log.C_LOG_NOTHING
visualize = False
# 3.3 Create your scenario and run some cycles
myscenario = MyScenario(
p_mode=Mode.C_MODE_SIM,
p_ada=True,
p_cycle_limit=cycle_limit,
p_visualize=visualize,
p_logging=logging
)
myscenario.reset(p_seed=3)
myscenario.run()
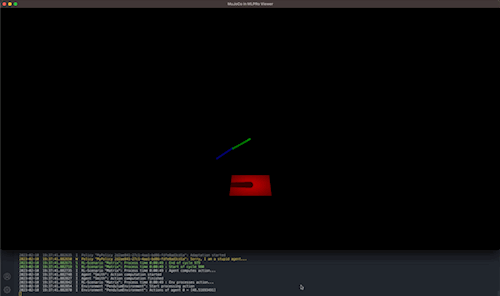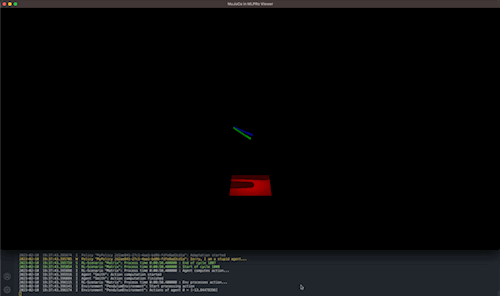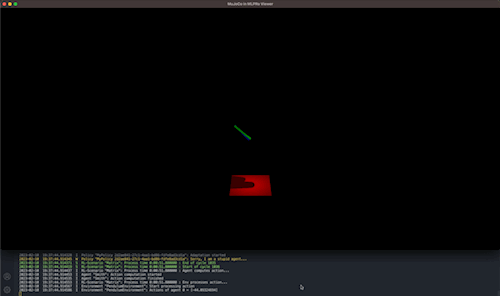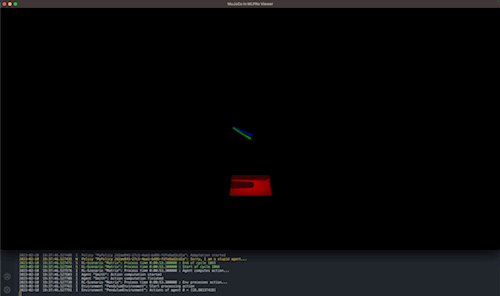
Results
Cross Reference