Cluster analysis
Ver. 1.3.1 (2024-08-21)
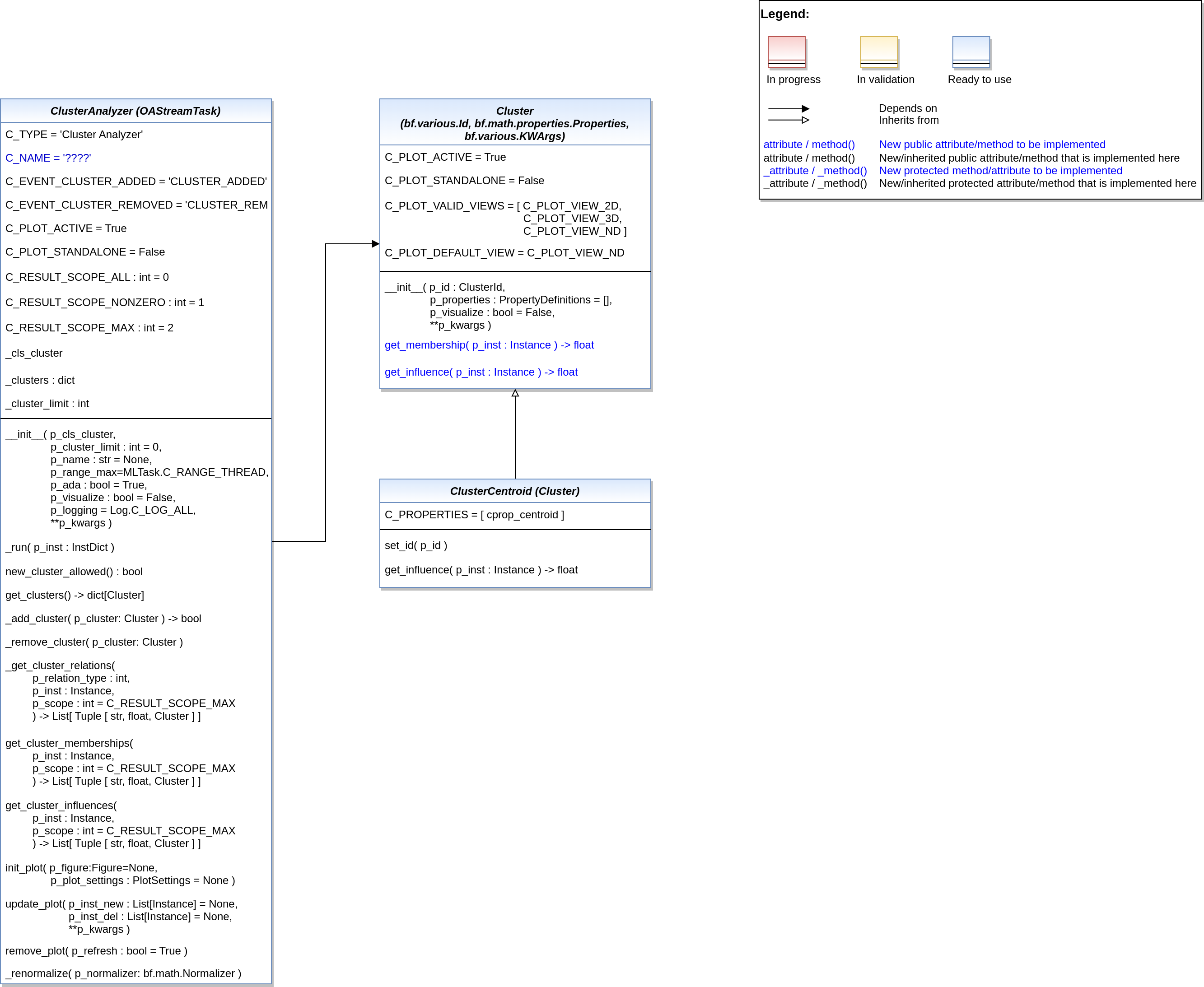
This module provides a template class for online cluster analysis.
- class mlpro.oa.streams.tasks.clusteranalyzers.basics.ClusterAnalyzer(p_cls_cluster: type = <class 'mlpro.oa.streams.tasks.clusteranalyzers.clusters.basics.Cluster'>, p_cluster_limit: int = 0, p_name: str = None, p_range_max=1, p_ada: bool = True, p_duplicate_data: bool = False, p_visualize: bool = False, p_logging=True, **p_kwargs)
Bases:
OAStreamTaskBase class for online cluster analysis. It raises an event when a cluster was added or removed.
Steps to implement a new algorithm are: - Create a new class and inherit from this base class - Specify all cluster properties provided/maintained by your algorithm in C_CLUSTER_PROPERTIES. - Implement method self._adapt() to update your cluster list on new instances - Implement method self._adapt_reverse() to update your cluster list on obsolete instances - New cluster: hand over self._cluster_properties.values() on instantiation
- Parameters:
p_cls_cluster – Cluster class (Class Cluster or a child class).
p_cluster_limit (int) – Optional limit for clusters to be created. Default = 0 (no limit).
p_name (str) – Optional name of the task. Default is None.
p_range_max (int) – Maximum range of asynchonicity. See class Range. Default is Range.C_RANGE_PROCESS.
p_ada (bool) – Boolean switch for adaptivitiy. Default = True.
p_duplicate_data (bool) – If True, instances will be duplicated before processing. Default = False.
p_visualize (bool) – Boolean switch for visualisation. Default = False.
p_logging – Log level (see constants of class Log). Default: Log.C_LOG_ALL
p_kwargs (dict) – Further optional named parameters.
- C_RESULT_SCOPE_ALL
Result scope, that includes all clusters
- Type:
int = 0
- C_RESULT_SCOPE_NONZERO
Result scope, that includes just clusters with result values > 0
- Type:
int = 1
- C_RESULT_SCOPE_MAX
Result scope, that includes just the cluster with the highest result value.
- Type:
int = 2
- C_CLUSTER_PROPERTIES
List of cluster properties supported/maintained by the algorithm. These properties are handed over to each new cluster.
- Type:
PropertyDefinitions
- C_TYPE = 'Cluster Analyzer'
- C_EVENT_CLUSTER_ADDED = 'CLUSTER_ADDED'
- C_EVENT_CLUSTER_REMOVED = 'CLUSTER_REMOVED'
- C_PLOT_ACTIVE: bool = True
- C_PLOT_STANDALONE: bool = False
- C_RESULT_SCOPE_ALL: int = 0
- C_RESULT_SCOPE_NONZERO: int = 1
- C_RESULT_SCOPE_MAX: int = 2
- C_CLUSTER_PROPERTIES: List[Tuple[str, int, bool, type]] = []
- align_cluster_properties(p_properties: List[Tuple[str, int, bool, type]]) list
Aligns list of cluster properties with the given list. In particular, the maximum derivative order of numeric properties is aligned.
- Parameters:
p_properties (PropertyDefinitions) – List of properties to be aligned with.
Returns
list – List of unknown properties.
- _run(p_inst: Dict[int, Tuple[str, Instance]])
Custom method that is called by method run().
- Parameters:
p_inst (InstDict) – Instances to be processed.
- new_cluster_allowed() bool
Determines whether adding a new cluster is allowed.
- Returns:
True, if adding a new cluster allowed. False otherwise.
- Return type:
bool
- get_cluster_cls()
- get_clusters() dict[Cluster]
This method returns the current list of clusters.
- Returns:
dict_of_clusters – Current dictionary of clusters.
- Return type:
dict[Cluster]
- _get_next_cell_id() int
- _add_cluster(p_cluster: Cluster) bool
Protected method to be used to add a new cluster. Please use as part of your algorithm. Please use method new_cluster_allowed() before adding a cluster.
- Parameters:
p_cluster (Cluster) – Cluster object to be added.
- _remove_cluster(p_cluster: Cluster)
Protected method to remove an existing cluster. Please use as part of your algorithm.
- Parameters:
p_cluster (Cluster) – Cluster object to be added.
- _get_cluster_relations(p_relation_type: int, p_inst: Instance, p_scope: int) List[Tuple[int, float, object]]
Internal method to determine the relation of the given instance to each cluster as a value in percent. Currently supported relations are membership and influence.
See also: public methods get_cluster_memberships() and get_cluster influences()
- Parameters:
p_relation_type (int) – Possible values are 0 (cluster membership) and 1 (cluster influence)
p_inst (Instance) – Instance to be evaluated.
p_scope (int) – Scope of the result list. See class attributes C_RESULT_SCOPE_* for possible values.
- Returns:
results – List of result items which are tuples of a cluster id, a relative result value in [0,1] and a reference to the cluster object.
- Return type:
List[ResultItem]
- get_cluster_memberships(p_inst: Instance, p_scope: int = 2) List[Tuple[int, float, object]]
Method to determine the relative membership of the given instance to each cluster as a value in [0,1].
See also: method Cluster.get_membership().
- Parameters:
p_inst (Instance) – Instance to be evaluated.
p_scope (int) – Scope of the result list. See class attributes C_RESULT_SCOPE_* for possible values. Default value is C_RESULT_SCOPE_MAX.
- Returns:
List of membership items which are tuples of a cluster id, a relative membership value in [0,1], and a reference to the cluster object.
- Return type:
List[ResultItem]
- get_cluster_influences(p_inst: Instance, p_scope: int = 2) List[Tuple[int, float, object]]
Method to determine the relative influence of the given instance to each cluster as a value in [0,1].
See also: method Cluster.get_influence().
- Parameters:
p_inst (Instance) – Instance to be evaluated.
p_scope (int) – Scope of the result list. See class attributes C_RESULT_SCOPE_* for possible values. Default value is C_RESULT_SCOPE_MAX.
- Returns:
List of influence items which are tuples of a cluster id, a relative influence value in [0,1], and a reference to the cluster object.
- Return type:
List[ResultItem]
- init_plot(p_figure: Figure = None, p_plot_settings: PlotSettings = None)
Initializes the plot functionalities of the class.
- Parameters:
p_figure (Matplotlib.figure.Figure, optional) – Optional MatPlotLib host figure, where the plot shall be embedded. The default is None.
p_plot_settings (PlotSettings) – Optional plot settings. If None, the default view is plotted (see attribute C_PLOT_DEFAULT_VIEW).
- update_plot(p_inst: Dict[int, Tuple[str, Instance]] = None, **p_kwargs)
Specialized definition of method update_plot() of class mlpro.bf.plot.Plottable.
- Parameters:
p_inst (InstDict) – Instances to be plotted.
p_kwargs (dict) – Further optional plot parameters.
- remove_plot(p_refresh: bool = True)
” Removes the plot and optionally refreshes the display.
- Parameters:
p_refresh (bool = True) – On True the display is refreshed after removal
- _renormalize(p_normalizer: Normalizer)
Internal renormalization of all clusters. See method OATask.renormalize_on_event() for further information.
- Parameters:
p_normalizer (Normalizer) – Normalizer object to be applied on task-specific
Ver. 2.1.0 (2024-07-08)
This module provides a template class for clusters to be used in cluster analyzer algorithms.
- class mlpro.oa.streams.tasks.clusteranalyzers.clusters.basics.Cluster(p_id: int, p_properties: List[Tuple[str, int, bool, type]] = [], p_visualize: bool = False, **p_kwargs)
-
Universal template class for a cluster with any number of properties added by a cluster analyzer.
- Parameters:
p_id (ClusterId) – Unique cluster id.
p_properties (PropertyDefinitions) – List of property definitions.
p_visualize (bool) – Boolean switch for visualisation. Default = False.
p_kwargs (dict) – Further parameters.
- C_PLOT_ACTIVE: bool = True
- C_PLOT_STANDALONE: bool = False
- C_PLOT_VALID_VIEWS: list = ['2D', '3D', 'ND']
- C_PLOT_DEFAULT_VIEW: str = 'ND'
- C_CLUSTER_COLORS = ['brown', 'olive', 'orange', 'green', 'red', 'gray', 'purple', 'pink', 'cyan', 'blue']
- set_plot_color(p_color)
- get_membership(p_inst: Instance) float
Custom method to compute a scalar membership value for the given instance.
- Parameters:
p_inst (Instance) – Instance.
- Returns:
A scalar value in [0,1] that determines the given instance’s membership in this cluster. A value of 0 means that the given instance is not a member of the cluster at all while a value of 1 confirms full membership.
- Return type:
float
- get_influence(p_inst: Instance) float
Custom method to compute a scalar influence value for the given instance.
- Parameters:
p_inst (Instance) – Instance.
- Returns:
Scalar value >= 0 that determines the influence of the cluster on the specified instance. A value 0 means that the cluster has no influence on the instance at all.
- Return type:
float
- property color
Ver. 1.3.0 (2024-06-18)
This module provides templates for cluster analysis to be used in the context of online adaptivity.
- class mlpro.oa.streams.tasks.clusteranalyzers.clusters.centroid.ClusterCentroid(p_id: int, p_properties: List[Tuple[str, int, bool, type]] = [], p_visualize: bool = False, **p_kwargs)
Bases:
ClusterExtended cluster class with a centroid.
- centroid
Centroid object.
- Type:
Centroid
- C_PROPERTIES: PropertyDefinitions = [('centroid', 0, False, <class 'mlpro.oa.streams.tasks.clusteranalyzers.clusters.properties.centroid.Centroid'>)]
- set_id(p_id)
Sets/generates a new id.
- Parameters:
p_id – Optional external id. If None, a unique id is generated.