In RL, an agent is an autonomous entity that interacts with an environment.
It receives rewards for performing specific actions and adjusts its behavior based on the feedback received.
The agent’s goal is to learn a policy that maximizes its cumulative reward over time.
From a scientific perspective, the agent is typically modeled as a decision-making system that maps environmental states to actions through a policy.
This policy can be either deterministic or probabilistic, and it can be learned using various RL algorithms such as Q-Learning, SARSA, or Policy Gradient methods.
The agent’s performance is evaluated using metrics such as the reward, cumulative reward, and value functions.
Overall, an agent in RL is an algorithm that makes decisions and learns from experience, aiming to optimize its performance in a given task.
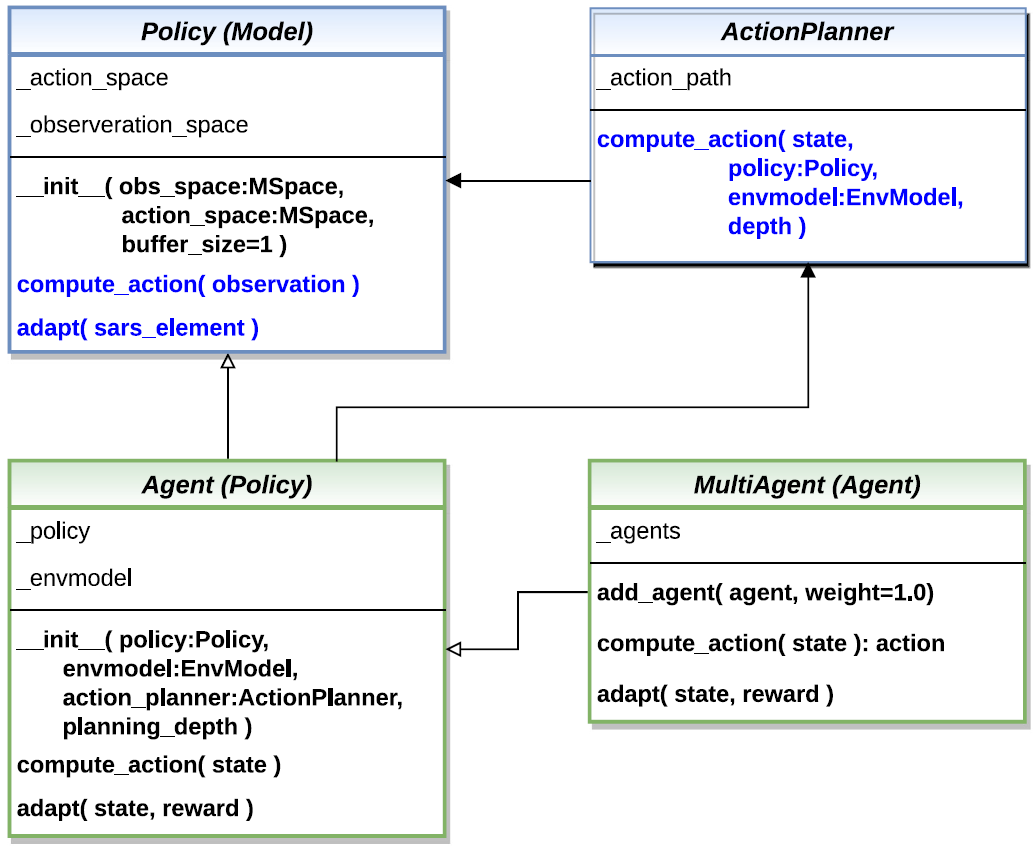
MLPro-RL Agent Models
MLPro-RL provides a specialized agent model landscape, which supports different RL scenarios, including single-agent RL, multi-agent RL, and model-based agents with an optional action planner.
Single-Agent RL: This scenario features a single agent that interacts with an environment.
Multi-Agent RL: Here, the structure involves assigning multiple single agents within a group, where agents may interact or collaborate.
Model-Based RL: In this case, the agent incorporates a model of the environment to make more informed decisions. Additionally, an action planner can be used to enhance the decision-making process.
The core component of each agent, whether in single-agent or multi-agent RL, is the policy.
The basic policy class inherits from the MLPro Model and is extended with RL-specific functions for action calculation.
Users can either:
Extend the policy class to implement their own custom algorithms (see own custom algorithms).
Use third-party algorithms via the provided wrapper classes (see wrapper classes).
For model-based RL scenarios, an environment model (known as the EnvModel class) can be added to a single agent.
This class allows the agent to learn the dynamics or behavior of the environment.
Another extension of model-based agents is the action planner, which uses the environment model (or EnvModel) to plan the next action by predicting the output over a certain horizon.
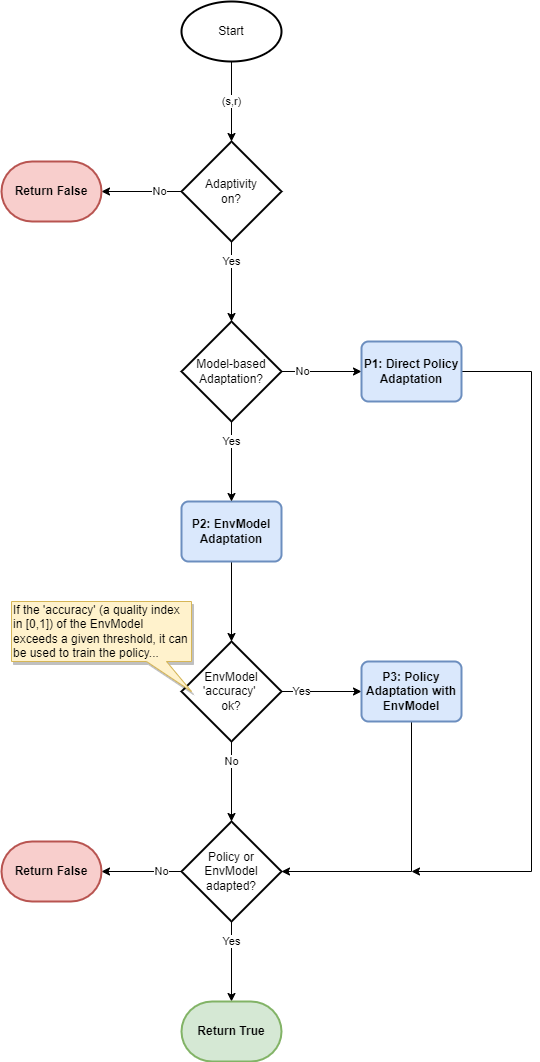
The following flowchart illustrates the agent adaptation procedure. Initially, the loop checks whether it is a model-based RL or model-free RL.
If it is model-free RL, the loop proceeds directly to policy adaptation, and the current step ends after the adaptation.
For model-based RL, the EnvModel is first adapted. Then, the loop checks whether the accuracy of the EnvModel exceeds a specified threshold. This ensures that the model is sufficiently accurate for policy adaptation. If the accuracy is above the threshold, policy adaptation occurs using the EnvModel; otherwise, the current step ends without any policy adaptation.