7.3.1. Developing custom environments
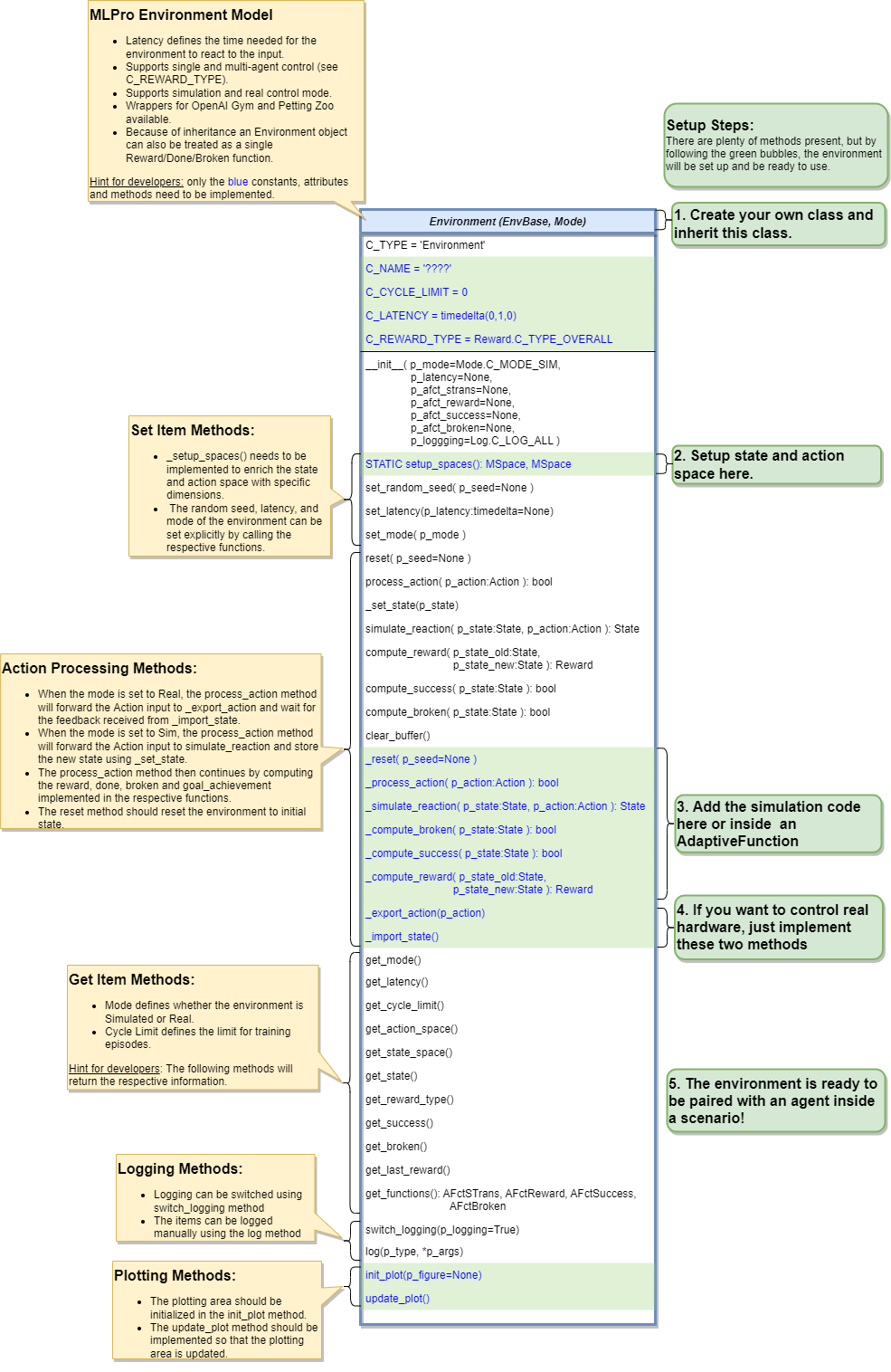
Environment creation
Creating an environment that satisfies the MLPro interface is straightforward and easy to implement. Essentially, a custom MLPro environment is ready to use by defining a class with four main functions:
setup_space,
_reset,
_simulate_reaction, and
_compute_reward.
Additionally, two optional functions, _compute_broken and _compute_success, can be implemented. If they are not defined, they will default to returning False, which means the environment will continue running until the cycle time is reached or an external stop command (such as the end of an episode) is triggered.
Each environment must implement the following MLPro functions:
from mlpro.rl.models import * class MyEnvironment(Environment): """ Custom Environment that satisfies mlpro interface. """ C_NAME = 'MyEnvironment' C_LATENCY = timedelta(0,1,0) # Default latency 1s C_REWARD_TYPE = Reward.C_TYPE_OVERALL # Default reward type @staticmethod def setup_spaces(): """ Static template method to set up and return state and action space of environment. """ # Setup state space example # state_space = ESpace() # state_space.add_dim(Dimension(0, 'Pos', 'Position', '', 'm', 'm', [-50,50])) # state_space.add_dim(Dimension(1, 'Vel', 'Velocity', '', 'm/sec', '\frac{m}{sec}', [-50,50])) # Setup action space example # action_space = ESpace() # action_space.add_dim(Dimension(0, 'Rot', 'Rotation', '', '1/sec', '\frac{1}{sec}', [-50,50])) # return state_space, action_space .... def _simulate_reaction(self, p_state: State, p_action: Action, p_step:timedelta = None) -> State: """ Parameters ---------- p_state : State Current state. p_action : Action Action. Returns ------- State Subsequent state after transition """ .... def _reset(self, p_seed=None) -> None: """ Reset the system to an initial/defined state Parameters ---------- p_seed : int Seed parameter for an internal random generator """ .... def _compute_reward(self, p_state_old: State = None, p_state_new: State = None) -> Reward: """ Computes a reward based on a predecessor and successor state. Parameters ---------- p_state_old : State Predecessor state. p_state_new : State Successor state. Returns ------- Reward Reward """ .... def _compute_success(self, p_state: State) -> bool: """ Assesses the given state whether it is a 'success' state. Parameters ---------- p_state : State State to be assessed. Returns ------- success : bool True, if the given state is a 'success' state. False otherwise. """ .... def _compute_broken(self, p_state: State) -> bool: """ Assesses the given state whether it is a 'broken' state. Parameters ---------- p_state : State State to be assessed. Returns ------- success : bool True, if the given state is a 'broken' state. False otherwise. """ ....
One of the advantages of using MLPro is the flexibility of reward structures, which are particularly useful for Multi-Agent RL approach. The framework supports three types of reward structures:
C_TYPE_OVERALL: The default reward type, which provides a scalar value representing the overall reward.
C_TYPE_EVERY_AGENT: A scalar reward for each individual agent.
C_TYPE_EVERY_ACTION: A scalar reward for each agent-action pair.
Additionally, MLPro offers two operational modes: simulation mode and real hardware mode. For real hardware mode, the environment creation process r112 We will soon provide a built-in testing module within MLPro and detailed instructions on how to execute these tests, along with examples.