Howto RL-011: Train a wrapped Stable Baslines 3 policy on MLPro’s native UR5 environment (Paper)
Prerequisites
- Please install the following packages to run this examples properly:
Executable code
## -------------------------------------------------------------------------------------------------
## -- Project : MLPro - A Synoptic Framework for Standardized Machine Learning Tasks
## -- Package : mlpro
## -- Module : howto_rl_011_train_ur5_environment_with_wrapped_sb3_policy.py
## -------------------------------------------------------------------------------------------------
## -- History :
## -- yyyy-mm-dd Ver. Auth. Description
## -- 2021-11-18 0.0.0 MRD Creation
## -- 2021-11-18 1.0.0 MRD Initial Release
## -- 2021-12-07 1.0.1 DA Refactoring
## -- 2022-02-11 1.1.0 DA Special derivate for publication
## -- 2022-05-23 1.2.0 MRD Add visualize toggle on UR5JointControl for gazebo GUI
## -- 2022-06-06 1.2.1 MRD Add real connection option
## -- 2022-06-13 1.2.2 MRD Update possibility to run separate simulator and training
## -- setting separate ROS Server IP
## -------------------------------------------------------------------------------------------------
"""
Ver. 1.2.2 (2022-06-13)
This module shows how to use SB3 wrapper to train UR5 robot (derivate for paper).
"""
from mlpro.rl.models import *
from mlpro.rl.pool.envs.ur5jointcontrol import UR5JointControl
from stable_baselines3 import PPO
from mlpro.wrappers.sb3 import WrPolicySB32MLPro
from pathlib import Path
# 1 Implement your own RL scenario
class ScenarioUR5A2C(RLScenario):
C_NAME = 'Matrix'
def _setup(self, p_mode, p_ada, p_logging):
# 1.1 Setup environment
self._env = UR5JointControl(
p_build=True,
p_real=p_mode,
p_start_simulator=True,
p_start_ur_driver=True,
# p_ros_server_ip="172.19.10.199",
p_net_interface="enp0s31f6",
p_robot_ip="172.19.10.41",
# p_reverse_ip="172.19.10.140",
p_visualize=self._visualize,
p_logging=p_logging)
policy_sb3 = PPO(
policy="MlpPolicy",
n_steps=20,
env=None,
_init_setup_model=False,
device="cpu",
seed=1)
policy_wrapped = WrPolicySB32MLPro(
p_sb3_policy=policy_sb3,
p_cycle_limit=self._cycle_limit,
p_observation_space=self._env.get_state_space(),
p_action_space=self._env.get_action_space(),
p_ada=p_ada,
p_logging=p_logging)
# 1.2 Setup standard single-agent with own policy
return Agent(
p_policy=policy_wrapped,
p_envmodel=None,
p_name='Smith',
p_ada=p_ada,
p_logging=p_logging
)
# 2 Train agent in scenario
now = datetime.now()
training = RLTraining(
p_scenario_cls=ScenarioUR5A2C,
p_env_mode=Mode.C_MODE_SIM,
p_cycle_limit=5000,
p_cycles_per_epi_limit=-1,
p_collect_states=True,
p_collect_actions=True,
p_collect_rewards=True,
p_collect_training=True,
p_visualize=True,
p_path=str(Path.home()),
p_logging=Log.C_LOG_WE)
training.run()
Results
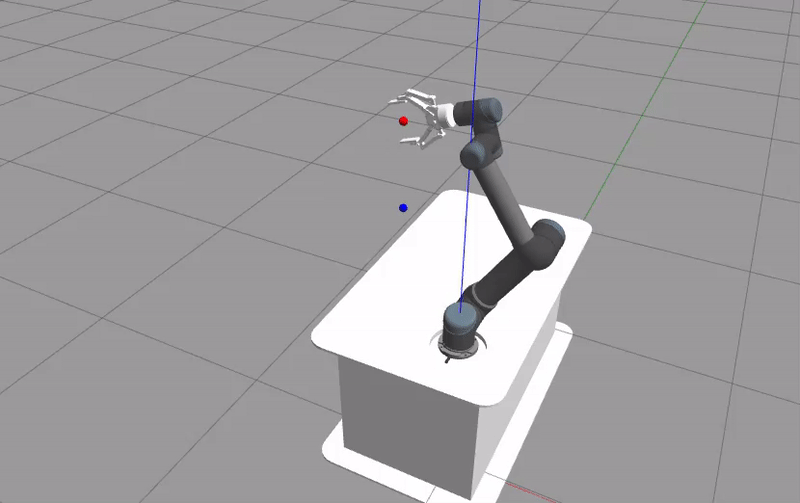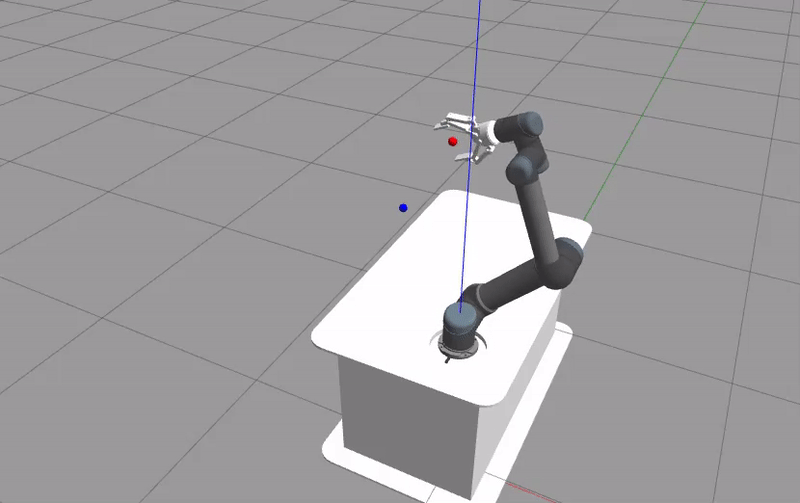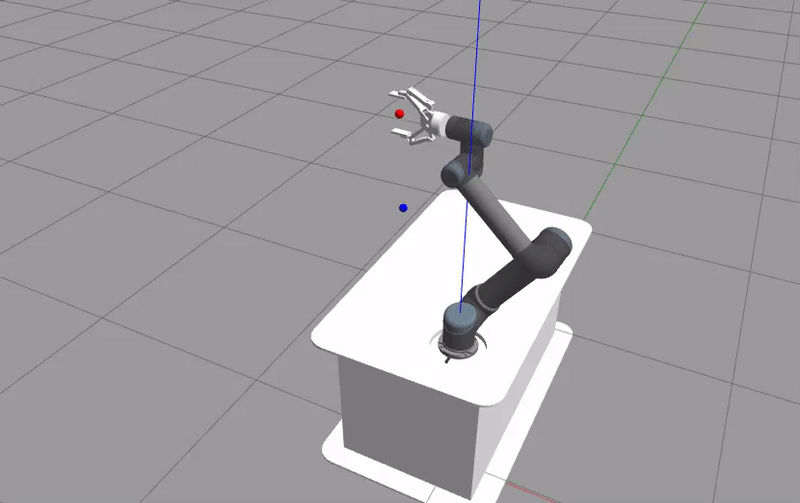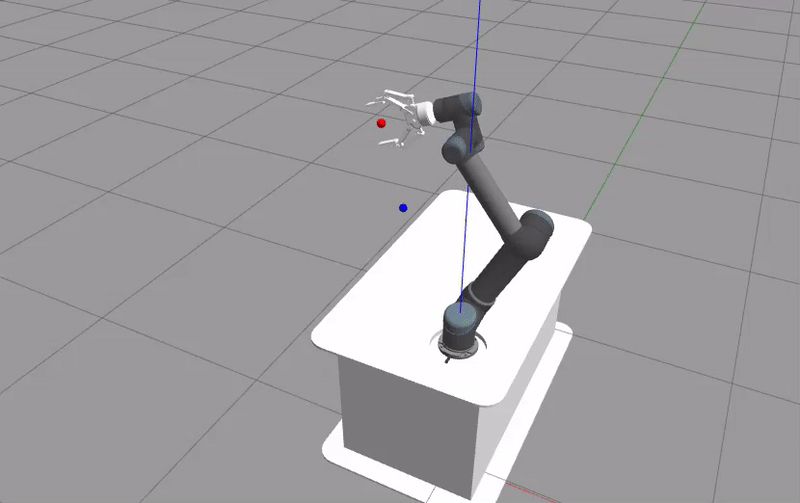
The Gazebo GUI should be the first thing that shows up. The UR5 robot will move depending on the given action and the training is run. When the training is done, the logged rewards will be plotted using the matplotlib library.
The plotted figure is not reproducible due to the simulator’s nature of simulating real world scenario. Although seeds can be set for the random generator, the sampling cannot be done at the exact same time during different runs. For a more reproducible results, Howto RL-012 is more appropriate.