7.1. Overview
MLPro-RL is the first ready-to-use subpackage in MLPro, designed specifically for reinforcement learning (RL)-related activities. It provides comprehensive base classes for core RL components, including agents, environments, policies, multi-agent systems, and training frameworks. The training loop follows the Markov Decision Process (MDP) model, as illustrated in the diagram below.
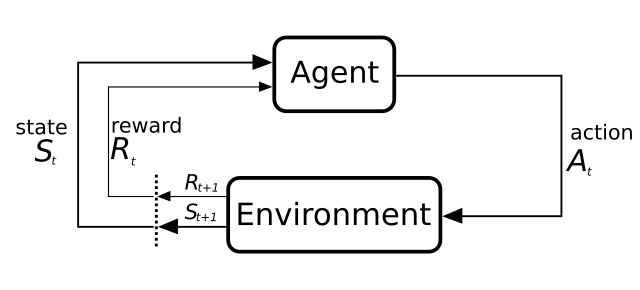
This figure is adapted from Sutton and Barto, licensed by CC BY-NC-ND 2.0.
Markov Decision Process (MDP)
An MDP consists of two primary components: the environment and the agent.
Agent: The decision-maker that selects actions based on its policy, considering the current state of the environment.
Environment: The surrounding system in which the agent operates and interacts. The environment’s condition is represented by states.
MDP models the interaction between the agent and the environment. The agent chooses an action and submits it to the environment, which then reacts by altering its state. The environment provides feedback in the form of a new state and a reward, indicating the consequences of the action. Through continuous interactions, the agent refines its policy to achieve optimal performance.
Why Choose MLPro-RL?
MLPro-RL supports a wide range of RL training configurations, including:
Model-free and model-based RL
Single-agent and multi-agent systems
Simulated and real hardware implementations
This versatility makes MLPro-RL a valuable tool for students, educators, RL engineers, and researchers looking for a standardized and flexible RL framework. The structure of MLPro-RL is depicted in the following figure:
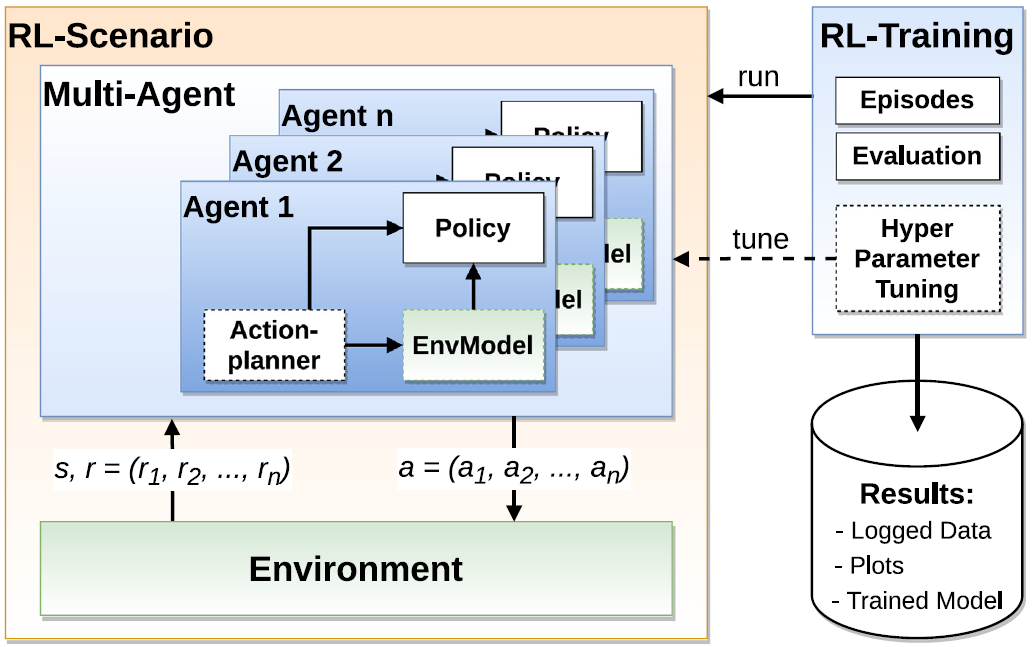
This figure is sourced from MLPro 1.0 paper.
To begin using MLPro-RL, you can easily import the RL modules with the following command:
from mlpro.rl import *
For a more comprehensive explanation of MLPro-RL, including a sample application on controlling a UR5 robot, refer to the paper: MLPro 1.0 - Standardized Reinforcement Learning and Game Theory in Python.
Learn more
Cross reference