Howto 15 - (RL) Train Robothtm with SB3 Wrapper
Ver. 1.0.2 (2021-12-08)
This module shows how to use SB3 wrapper to train Robothtm
Prerequisites
- Please install the following packages to run this examples properly:
Results
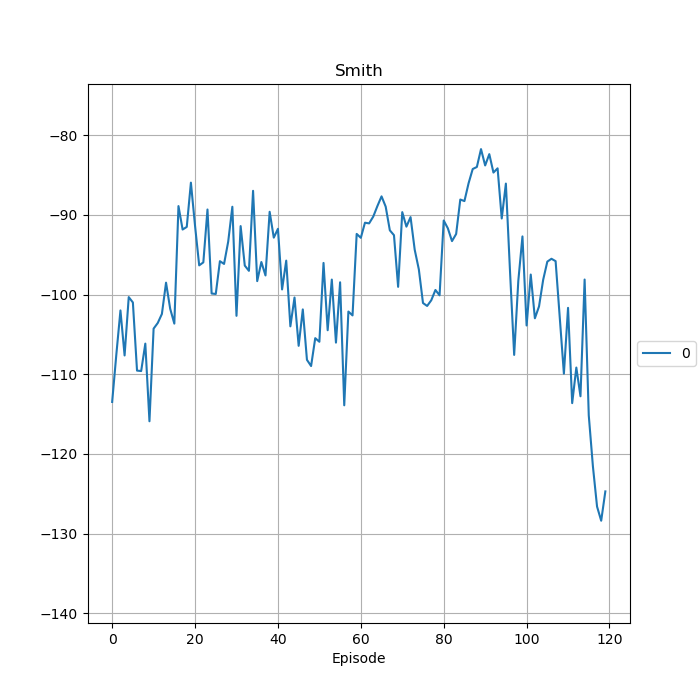
After the environment is initiated, the training will run for the specified amount of limits. However, it is noted that there is no visualization available for this environment. The training log is stored in the location specified and a figure plot similar to the figure above will be produced.
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: ------------------------------------------------------------------------------
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Training Results of run 0
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: ------------------------------------------------------------------------------
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: ------------------------------------------------------------------------------
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Scenario : RL-Scenario Matrix
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Model : Agent Smith
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Start time stamp : YYYY-MM-DD HH:MM:SS.SSSSSS
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- End time stamp : YYYY-MM-DD HH:MM:SS.SSSSSS
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Duration : 0:00:59.209252
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Start cycle id : 0
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- End cycle id : 11999
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Training cycles : 12000
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Evaluation cycles : 12500
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Adaptations : 120
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- High score : -83.8038799825578
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Results stored in : "C:\Users\%username%\YYYY-MM-DD HH:MM:SS Training RL"
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Training Episodes : 120
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: -- Evaluations : 25
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: ------------------------------------------------------------------------------
YYYY-MM-DD HH:MM:SS.SSSSSS W Results RL: ------------------------------------------------------------------------------
- In the folder, there should be some files including:
agent_actions.csv
env_rewards.csv
env_states.csv
evaluation.csv
summary.csv
trained model.pkl
Example Code
## -------------------------------------------------------------------------------------------------
## -- Project : FH-SWF Automation Technology - Common Code Base (CCB)
## -- Package : mlpro
## -- Module : Train Robothtm with SB3 Wrapper
## -------------------------------------------------------------------------------------------------
## -- History :
## -- yyyy-mm-dd Ver. Auth. Description
## -- 2021-12-01 0.0.0 MRD Creation
## -- 2021-12-01 1.0.0 MRD First Release
## -- 2021-12-07 1.0.1 DA Refactoring
## -- 2021-12-08 1.0.2 MRD Add parameter to change the hidden layer of the policy
## -------------------------------------------------------------------------------------------------
"""
Ver. 1.0.2 (2021-12-08)
This module shows how to use SB3 wrapper to train Robothtm
"""
import torch
from mlpro.rl.models import *
from mlpro.rl.pool.envs.robotinhtm import RobotHTM
from stable_baselines3 import PPO
from mlpro.wrappers.sb3 import WrPolicySB32MLPro
from pathlib import Path
# 1 Implement your own RL scenario
class ScenarioRobotHTM(RLScenario):
C_NAME = 'Matrix'
def _setup(self, p_mode, p_ada, p_logging):
# 1 Setup environment
self._env = RobotHTM(p_target_mode="fix", p_logging=True)
policy_kwargs = dict(activation_fn=torch.nn.Tanh,
net_arch=[dict(pi=[128, 128], vf=[128, 128])])
policy_sb3 = PPO(
policy="MlpPolicy",
n_steps=100,
env=None,
_init_setup_model=False,
policy_kwargs=policy_kwargs,
device="cpu",
seed=2)
policy_wrapped = WrPolicySB32MLPro(
p_sb3_policy=policy_sb3,
p_cycle_limit=self._cycle_limit,
p_observation_space=self._env.get_state_space(),
p_action_space=self._env.get_action_space(),
p_ada=p_ada,
p_logging=p_logging)
# 2 Setup standard single-agent with own policy
return Agent(
p_policy=policy_wrapped,
p_envmodel=None,
p_name='Smith',
p_ada=p_ada,
p_logging=p_logging
)
# 2 Create scenario and start training
if __name__ == "__main__":
# 3.1 Parameters for demo mode
cycle_limit = 100000
adaptation_limit = 150
stagnation_limit = 5
eval_frequency = 5
eval_grp_size = 5
logging = Log.C_LOG_WE
visualize = True
path = str(Path.home())
plotting = True
else:
# 3.2 Parameters for internal unit test
cycle_limit = 50
adaptation_limit = 5
stagnation_limit = 5
eval_frequency = 2
eval_grp_size = 1
logging = Log.C_LOG_NOTHING
visualize = False
path = None
plotting = False
# 3 Train agent in scenario
now = datetime.now()
training = RLTraining(
p_scenario_cls=ScenarioRobotHTM,
p_cycle_limit=cycle_limit,
p_cycles_per_epi_limit=100,
p_adaptation_limit=adaptation_limit,
p_stagnation_limit=stagnation_limit,
p_eval_frequency=eval_frequency,
p_eval_grp_size=eval_grp_size,
p_score_ma_horizon=7,
p_path=path,
p_visualize=visualize,
p_logging=logging
)
training.run()
# 4 Create Plotting Class
class MyDataPlotting(DataPlotting):
def get_plots(self):
"""
A function to plot data
"""
for name in self.data.names:
maxval = 0
minval = 0
if self.printing[name][0]:
fig = plt.figure(figsize=(7, 7))
raw = []
label = []
ax = fig.subplots(1, 1)
ax.set_title(name)
ax.grid(True, which="both", axis="both")
for fr_id in self.data.frame_id[name]:
raw.append(np.sum(self.data.get_values(name, fr_id)))
if self.printing[name][1] == -1:
maxval = max(raw)
minval = min(raw)
else:
maxval = self.printing[name][2]
minval = self.printing[name][1]
label.append("%s" % fr_id)
ax.plot(raw)
ax.set_ylim(minval - (abs(minval) * 0.1), maxval + (abs(maxval) * 0.1))
ax.set_xlabel("Episode")
ax.legend(label, bbox_to_anchor=(1, 0.5), loc="center left")
self.plots[0].append(name)
self.plots[1].append(ax)
if self.showing:
plt.show()
else:
plt.close(fig)
# 5 Plotting 1 MLpro
data_printing = {"Cycle": [False],
"Day": [False],
"Second": [False],
"Microsecond": [False],
"Smith": [True, -1]}
mem = training.get_results().ds_rewards
mem_plot = MyDataPlotting(mem, p_showing=plotting, p_printing=data_printing)
mem_plot.get_plots()