7.4.1. Custom policies
Policy creation
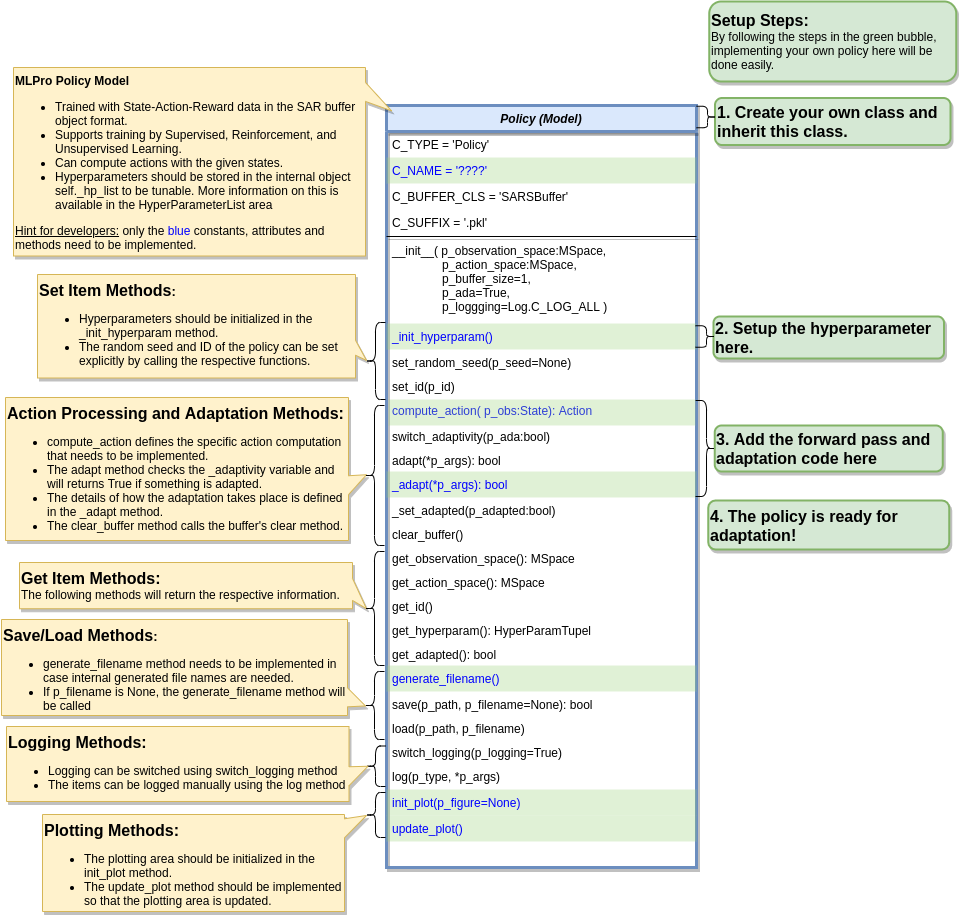
Creating a custom RL policy that satisfies the MLPro interface is straightforward. To begin, users need to inherit from the base Policy class. Afterward, users can define their custom policies by implementing at least two core functions: compute_action and _adapt, as demonstrated in the code below.
The compute_action method calculates the action to take in the current state.
The **_adap**t method optimizes the policy based on past experiences.
Here’s a sample implementation:
from mlpro.rl.models import * class MyPolicy (Policy): """ Creates a policy that satisfies mlpro interface. """ C_NAME = 'MyPolicy' def compute_action(self, p_state: State) -> Action: """ Specific action computation method to be redefined. Parameters: p_state State of environment Returns: Action object """ .... def _adapt(self, p_sars_elem:SARSElement) -> bool: """ Adapts the policy based on State-Action-Reward-State (SARS) data. Parameters ---------- p_sars_elem : SARSElement Object of type SARSElement. Returns ------- adapted : bool True, if something has been adapted. False otherwise. """ ....
Hyperparameters
The hyperparameters of the policy should be stored in the internal object self._hp_list, so that they can be adjusted externally. The _init_hyperparam method can be used to initialize these hyperparameters. For instructions on setting up a hyperparameter space, please refer to our how-to file.
Policy from Third-Party Packages
Alternatively, users can apply algorithms from Stable Baselines 3 by utilizing the relevant wrappers developed for integrating third-party packages with MLPro. For more information on this, please click here.
Algorithm Checker
A unit test script to verify the developed policies will be available soon!