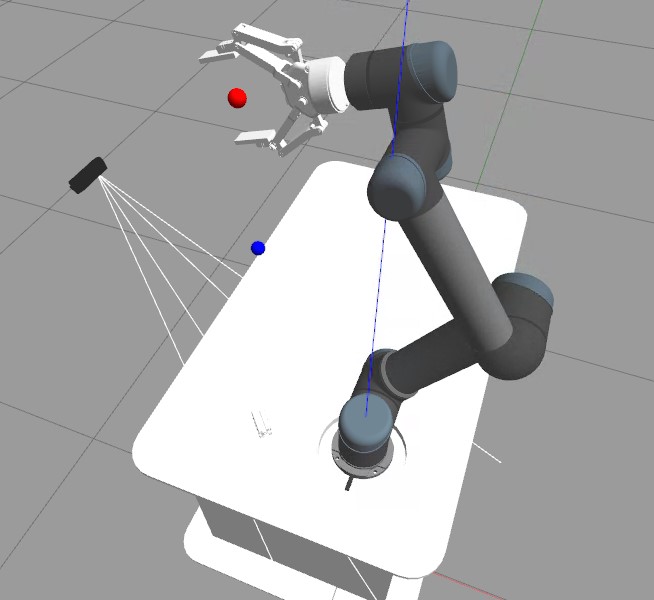
Universal Robots 5 Joint Control
This UR5 environment can be installed via:
import mlpro.rl.pool.envs.ur5jointcontrol
- 3rd Party Dependencies
The environment has been tested in Ubuntu 20.04 running ROS Noetic.
- The installation steps are as follow:
Install Ubuntu 20.04
Install ROS
Install Moveit
- Install Dependencies:
- Build the Environment:
- Source the package:
- Change the ros_ws_abspath parameter in:
Overview
General information
Parameter
Value
Agents
1
Native Source
MLPro
Action Space Dimension
[6,]
Action Space Base Set
Real number
Action Space Boundaries
[-0.1, 0.1]
State Space Dimension
[6,]
State Space Base Set
Real number
State Space Boundaries
[-2.0, 2.0]
Reward Structure
Overall reward
Action space
The action of the agent directly affects the joint angles (rad) of the robot. The action is interpreted as increments towards the current value.
Actuator
Parameter
Boundaries
Shoulder Pan Joint
rad
[-0.1, 0.1]
Shoulder Lift Joint
rad
[-0.1, 0.1]
Elbow Joint
rad
[-0.1, 0.1]
Wrist 1 Joint
rad
[-0.1, 0.1]
Wrist 2 Joint
rad
[-0.1, 0.1]
Wrist 3 Joint
rad
[-0.1, 0.1]
State space
The state space consists of position information of the end effector (Red Ball) and the target location (Blue Ball).
Element
Parameter
Boundaries
PositionX
m
[-2.0, 2.0]
PositionY
m
[-2.0, 2.0]
PositionZ
m
[-2.0, 2.0]
Targetx
m
[-2.0, 2.0]
Targety
m
[-2.0, 2.0]
Targetz
m
[-2.0, 2.0]
Reward structure
distance = np.linalg.norm(np.array(observations[:3]) - np.array(observations[3:])) ratio = distance/self.init_distance reward = -np.ones(1)*ratio reward = reward - 10e-3 if done: reward += self.reached_goal_reward
Version structure
Version 1.0.0 : Initial version release in MLPro v. 0.0.0